

2026.01.19
GORMで「検索条件が効かない!?」と焦った話。構造体検索の落とし穴と解決策
2024.01.25
DB【弊社紹介】社内勉強会開催!〜SQL高速化のために〜
本稿をご覧いただいております皆様こんにちは。MTです。
先月になりますが、弊社内の開発ユニットが持ち回りで実施している勉強会が再び開催されたので、今回もそのご紹介をしたいと思います。
今回はクイズもあるので、目を通していただけると嬉しいです。
今回の勉強会のテーマは、インデックスを主としたSQL高速化です。
インデックスは、予めソートした索引列を作成しておくことで、検索の高速化を行います。
インデックスはとても便利なものですが、扱い方によってはむしろパフォーマンスを落とす事になります。
今回の勉強会では、この扱いを間違わないために、様々なケースをテストした結果を比較検討したものをクイズとして発表していました。
本稿では、その勉強会の内容として、インデックスのもう少し詳しい紹介と、そのクイズを掲載します。
インデックスは前述の通り、あらかじめソートした索引列によって検索を高速化するものです。
インデックスが無い場合だと、WHERE句で絞り込みをするとデータベース内の全レコードを探索して、その結果を表示します。データ数が少なければ問題ないかもしれませんが、業務で使うような莫大なデータをそれで検索すると、途方もない時間がかかりそうですね、、、
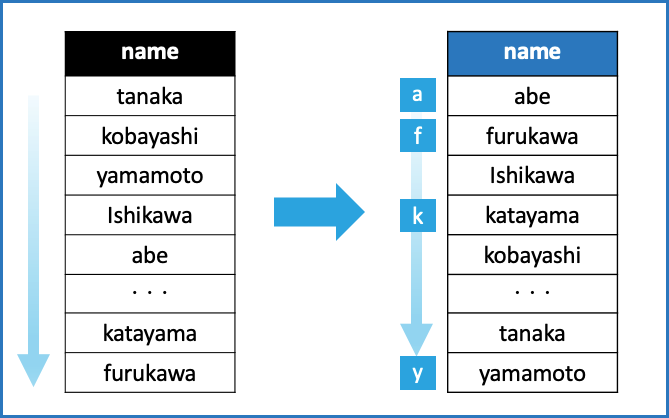
インデックスの例を示します。例えば下の画像のように人名のデータカラムがあれば、そのカラムの内容をアルファベット順に並べた索引が作成されます。これがインデックスです。
なぜこれで検索が早くなるのか、というとインデックスが保存されるデータ構造に理由があります。
インデックスは主にツリー構造と呼ばれるデータ構造によってデータが保存されます。例えば以下のような構造です。
(※今回の勉強会で扱ったMySQLのB+Tree構造の他にB-Tree構造を採用したデータベースも存在しますがここでは詳細説明を割愛します。主な構造の違いはB+Tree構造はデータが葉ノードにのみ存在し、葉ノード同士をつなぐポインタが存在する点です)

ご覧いただいております通り、アルファベット順に並んだ葉ノードを含む親ノードが、ある程度のサイズで区切られ、親ノードから一番近い子ノードを辿ることでデータに検索数を少なくしてアクセスができるようになっています。
読み込み速度が速くなる代わりに、書き込み速度が遅くなる
INSERT文の実行時に、テーブル内の全インデックスにデータを追加して探索用のツリー構造を最適化処理が走るためです。
したがって、インデックスを作成する際には、必要最小限にとどめる必要があります。
では、どのようなカラムがインデックスに向いているのでしょうか。
インデックスの目的から考えていきます。インデックスの目的、検索の効率化でしたね。
検索が効率化されるということは、インデックスによって絞り込める情報が広がる必要があります。
例えば、氏名、生年月日、性別を記載した名簿があったとして、どちらが個人の検索に有効でしょうか。
1:氏名に張る 2:性別に張る
性別での検索は、一般的な選択肢だと多くても3値ほどしか絞れず、検索結果として十分に絞り込めていない状態になります。
一方氏名での検索は、同姓同名の人がいる可能性があるので、必ず一つとは言わないが、ほぼ絞り込めますよね。したがって、「1:氏名に張る」の方が検索に有効だと考えられます。
このように、インデックスの選択性が高まるカラム、つまりデータの種類が多い(情報量の多い)カラムに対してインデックスを張るのが効果的です。
ちなみに、テーブル内で一意であることが約束されている「PRIMARY KEY制約」「UNIQUE制約」は選択性の高い値ですが、自動的にインデックスが作成されるため、改めて自分で作成する必要はありません。
また、インデックスによってどれほど効率化ができているか、そもそもインデックスが使えるのか、ということを確認しながら調整したい時は、EXPLAIN句で実行計画を表示するのが便利です。
COUNT句で件数を取得するときはインデックスは利用されるでしょうか?
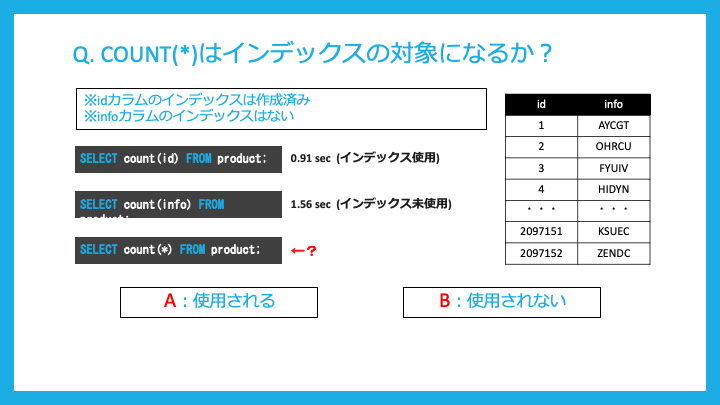
利用されます。
ただし使用しているDBがかなり前のものだと、対応していないことがあるようです。

LIKE句でワイルドカードを適用するとき、前方一致と部分一致でどちらが早いでしょうか?
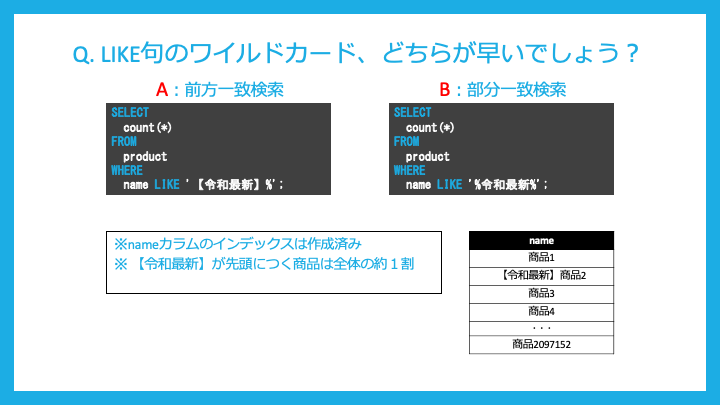
前方一致検索の方が早いです。
なぜならば、LIKE句はインデックス対象として、最初のワイルドカードまでを適用するためです。

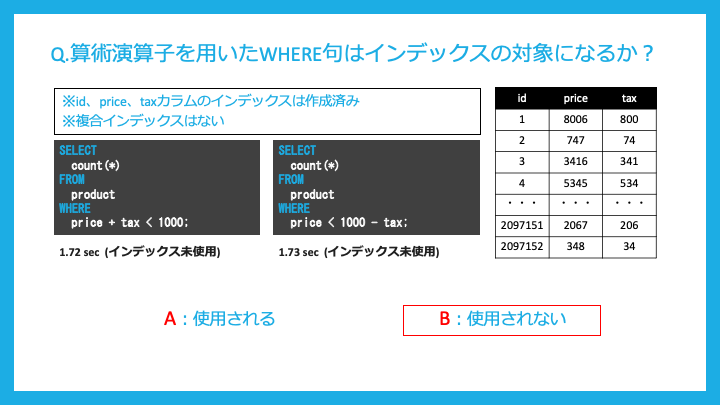
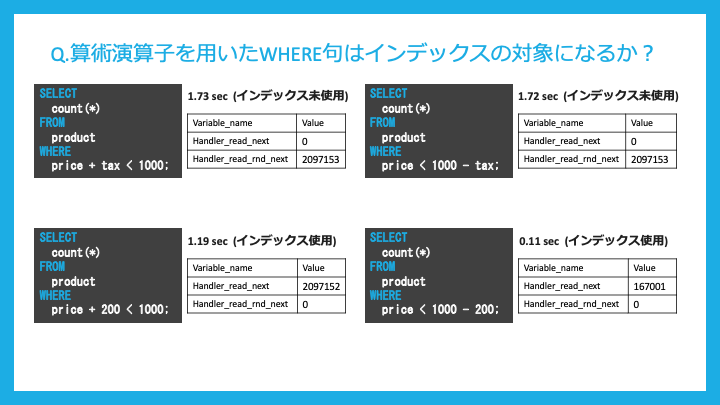
算術演算子を用いたWHERE句はインデックスの対象になるでしょうか?
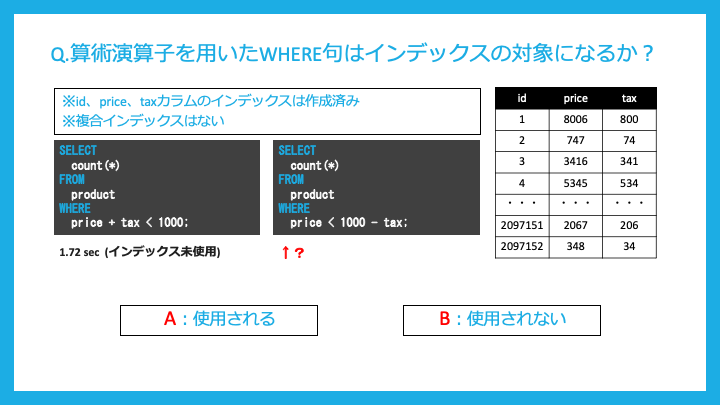
対象になりません。
補記のスライドにあるように、両辺に変数(カラム)が混ざっていない場合はインデックスの対象になります。
数値計算の方が優先度が高いためだそうです。
補記
IN句の記述を行うときデータの割合が多い物を、左(先)に置く場合と右(後)に置く場合、どちらが早いでしょうか?
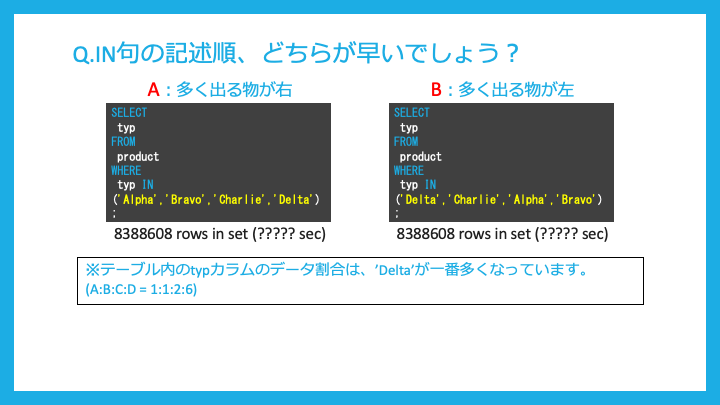
多く出るものを左に置いた方が早いです。
なぜなら多く出る物を先に絞り込んだほうが、その後で絞り込む対象が減るからです。
スライドにもあります通り、パフォーマンスは上がるが、可読性が下がる書き方になり得る点に注意が必要です。

アスタリスクと全カラム指定はどちらが早いでしょうか?

誤差レベルですが全指定の方が早いという結果になりました。
また、パフォーマンスの観点とは異なりますが、保守の観点でも全指定の方が望ましいです。

BETWEENと比較演算子ではどちらが早いでしょうか?
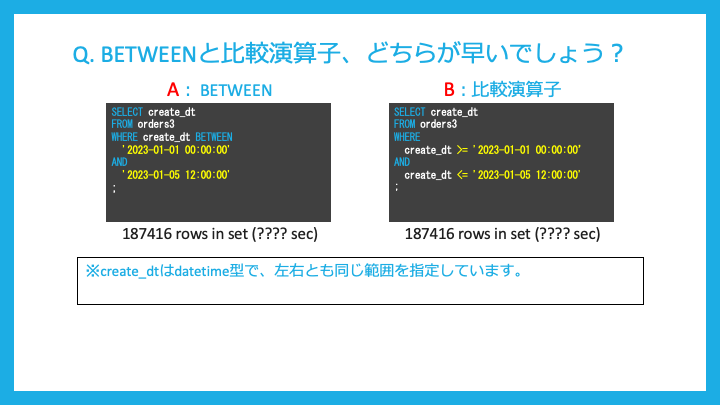
比較演算子の方が大幅に、早いです。
では、BETWEEN句は使わなくても良いのではないか?というところで次の問題です。

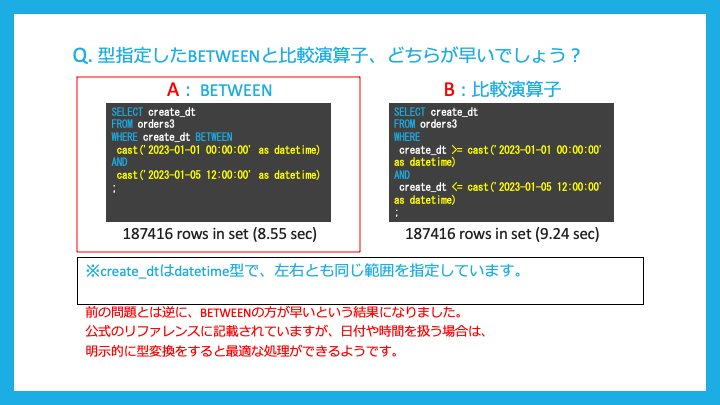
型指定した時に、BETWEENと比較演算子ではどちらが早いでしょうか?
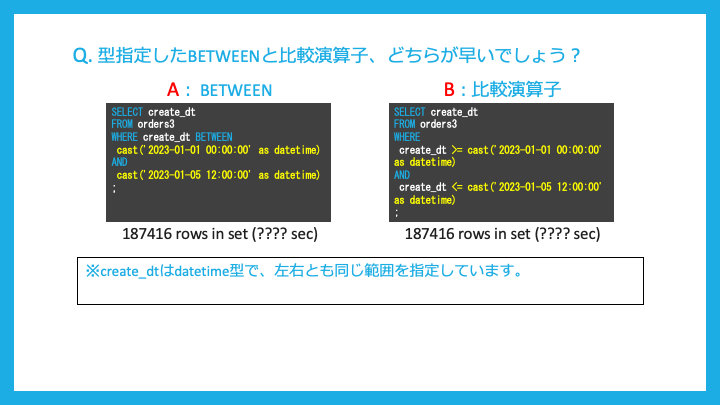
先ほどとは異なり、BETWEENの方が早くなります。
これは日付、時間に対しては明示的な型変換が最適な処理に必要であるためだそうです。
大文字の予約語と小文字の予約語、どちらが早いでしょうか?

誤差程度ではありますが、大文字の方が早くなるようです。
予約語の確認順序が原因と考えられます。

IN句とEXIST句ではどちらが早いでしょうか?

これまた誤差程度ではありますが、EXISTS句の方が早くなります。
これは評価順が影響していると考えられます。

DISTINCT句とEXIST句では、どちらが早いでしょうか?
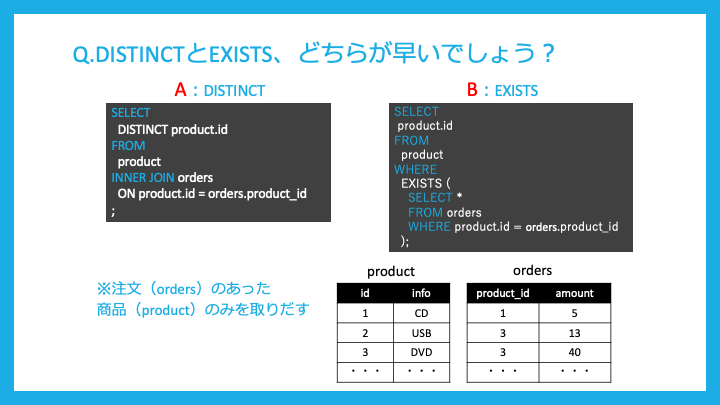
EXISTS句の方が早くなります。
これは挙動に大幅に差が有り、DISTINCTは重複削除のためのソートを挟むので、遅くなります。

複合インデックスを設定しているときに、インデックスの指定順とWEHERE条件の指定順は関係があるでしょうか?

関係があります。
複合インデックスを設定した順でWHERE条件を設定しないと、インデックスが使用されません。

【記事への感想募集中!】
記事への感想・ご意見がありましたら、ぜひフォームからご投稿ください!【テクノデジタルではエンジニア/デザイナーを積極採用中です!】
下記項目に1つでも当てはまる方は是非、詳細ページへ!Qangaroo(カンガルー)
【テクノデジタルのインフラサービス】
当社では、多数のサービスの開発実績を活かし、
アプリケーションのパフォーマンスを最大限に引き出すインフラ設計・構築を行います。
AWSなどへのクラウド移行、既存インフラの監視・運用保守も承りますので、ぜひご相談ください。
詳細は下記ページをご覧ください。
最近の記事
タグ検索

